- SELECT文
- 表構造の表示
- SELECTでの算術使用
- WHERE句
- ORDER BYによる行のソート
- SQL IN句
- CREATE句
- クエリの結合
- 「sql with」とは
- 概要:SQLの実行結果をファイル出力する
SELECT文
データベースの中からデータを取り出す文
例)
SELECT カラム1, カラム2, ... FROM データベース
SELECTによる射影
SELECT カラム1, カラム2 FROM データベース
列としてカラム1, カラム2だけを取り出している
全ての列のとりだし
SELECT * FROM データベース
SELECTによる選択
SELECT * FROM データベース WHERE 条件
例えば、社員データベースから部署コードが100であるものを選択したいときは
SELECT * FROM データベース WHERE データベース.部署コード = "100"
更なる複雑なWHERE句による選択は後ほど出てくる
表構造の表示
DESCRIBE
SELECTでの算術使用
selectの実行結果に対して計算を行うことができる。
例えば給料の12倍を示したいときは給料のカラムsalに*12を付け加える
SELECT empno, sal, sal*12 FROM 社員データベース
+は足し算
-は引き算
*は掛け算
/は割り算
さらに複雑な算術は()を使用して優先順位を指定する
SELECT empno, sal, (sal+1000)*12 FROM 社員データベース
列別名の使用
上記のsqlを実行するとsal*12がタグとして出てきてしまう。
これに対して独自のラベルをつけたいときは列別名を使う
列別名1
SELECT empno 社員番号, sal 給料, sal*12 年間給料予測 FROM 社員データベース
列別名2(ASを使用でも可能)
SELECT empno AS 社員番号, sal AS 給料, sal*12 AS 年間給料予測 FROM 社員データベース
列別名2(特殊文字を使用)
SELECT empno AS "社員No", sal AS "sal", sal*12 AS "WHERE" FROM 社員データベース
文字列の結合
||を使う
その際の文字列は'(単一引用ふ)でなければ行けない
SELECT empno || 'さんの入社日は' || hiredate FROM 社員データベース
代替引用符(q)演算子
'や?などの特殊な文字列を使いたい時はqの後に指定した文字列で区切ることでその区間だけは特殊文字列を使用できる
SELECT name || q'?'s Salary is : ?' || sal "Monthly Salary" FROM emplyoees;
sato's Salary : 5000
[]でも可能
SELECT name || q'['s Salary is : ]' || sal "Monthly Salary" FROM emplyoees;
重複行の削除
DISTINCTを使用
SELECT DISTINCT 部署コード FROM emplyoees;
これにより部署コードを重複なしで一覧で出すことができる
DISTINCTはselect内に一度しかかけず、二つ書くとエラーになる
複数列の重複行の削除
DISTINCTを使用して
部署コード, job二つが被ったものは重複としてみなすことができる
SELECT DISTINCT 部署コード, job FROM emplyoees;
同じ部署コード, jobは二度出てこない
WHERE句
WHERE句の基本
SELECT 列 FROM 表名 WHERE 列名 比較演算子 比較対象;
例)2000年の1月14日以降に生まれた従業員
SELECT empno 従業員番号 FROM employees WHERE birtday > '2000-01-14';
文字列や日付の比較
""で囲まなければいけない
大文字と小文字は区別される
名前がsatoで一件もヒットしなくても、SATOで引っかかる可能性はある
比較演算子
= 同じ値 > 大なり < 小なり > 以上 < 以下
WHERE句での列別名は使用ができない
次のSLEECT文はエラーになる
SELECT empno 従業員番号 FROM employees WHERE 従業員番号 > '1000';
原因は従業員番号がWHERE句で使用されているため
WHERE句では演算子が使える
従業員番号を2倍した時で1000と比較
SELECT empno 従業員番号 FROM employees WHERE empno*2 > '1000';
BETWEEN演算子
BETWEENの後に続く二つの数字の間にあるものが当てはまる
以下の例だと1000以上2000以下
1000と2000も含む
SELECT empno 従業員番号 FROM employees WHERE empno BETWEEN 1000 AND 2000;
BETWEENの日付での比較
日付の範囲もBETWEENで比較が可能
以下のSQLは
2000-01-14生まれの人から2000-10-14生まれの人までを含む
SELECT empno 従業員番号 FROM employees WHERE birtday BETWEEN '2000-01-14' and '2000-10-14';
IN演算子
資子を使用すると、列値と複数の値を比較できる
WHERE 列名 IN(値1,値2...)
次の例では10,20版の従業員番号に当てはまると結果にヒットする
SELECT empno, ename, deptno FROM employees WHERE deptno IN(10, 20);
次の例はその真逆で 10,20以外のものに当てはまるとヒットする
SELECT empno, ename, deptno FROM employees WHERE deptno IN(10, 20);
LIKE演算子
LIKE演算子を使うとさらに高度な文字列パターンで検索をかけられます
% 0文字以上の任意の文字列と一致する
_ 任意の文字列と一致する
例えば次の例では名前に鈴木を含む従業員を全て抽出しています
SELECT * FROM emplyoees WHEERE empname like "%鈴木%"
次の例では鈴木の後に三文字続く人を出力しています
SELECT * FROM emplyoees WHEERE empname like "%鈴木___"
ESCAPEオプション
%が文字列に入るものを認識したい時はさらに高度な技が必要になります。
そのためにはESCAPEオプションが役に立ちます
ESCAPEの後に任意の文字を指定することで、その文字をエスケープシークエンスとして扱うことができます
例えば以下の場合は50%を文字列として含むものを抽出できます
50%を50¥%として表記することで、%がワイルドカードとして認識されることを防げます
SELECT * FROM emplyoees WHEERE work_rate like "%50¥%%" ESCAPE '¥'
IS NULL演算子
IS NULLは値がNULLかどうかを比較することができます
つぎのselectはwork_rateがNULLになっている従業員を出力します
SELECT * FROM emplyoees WHEERE work_rate IS NULL
逆にNULL出ないものを抽出したい時は IS NOT NULLを使用します
SELECT * FROM emplyoees WHEERE work_rate IS NOT NULL
- ちなみにNULL稼働かの比較は,=では行えません。
AND演算子
前後に指定された条件が両方ともTRUEの場合にTRUE
OR演算子
前後に指定された条件のどちらか一方でもTRUEの場合にTRUE
INとORのパフォーマンスの違い
IN演算子は、内部的にはOR演算子を使用したものに置き換えられてしまう。
よって、
IN演算子を使用して書き換えても実行時のパフォーマンスは変わらない
テストに出ることもあるので覚えておきましょう
ORDER BYによる行のソート
ORDER BY句に列名を指定すると、ソートされたデータの抽出が可能になる。
同時に複数の列を指定することも可能(その場合は,区切る。左に書いたものほど優先度が高い)。
SELECT * FROM データベース WHERE 条件 ORDER BY 列名[,列名 ...];
ASCとDESCで並び替えを逆順にすることも可能
サンプル
SELECT * FROM employees ORDER BY sal;
このコードでは従業員データベースから給料順に並べている
「ASC」
昇順:小さいほうから順
デフォルトの設定はこちらになっている
「DESC」
降順:大きいほうから順
SELECT * FROM employees ORDER BY sal DESC;
こちらは意図的に設定しないと反映されない。
ORDER BYと列別名
ORDER BY句では列別名は使用可能
ソートの順序はデータによって異なる
例えば数値であれば、大きい順に並ぶ
日付であれば、最新の値順に並ぶ
NULLの扱いとORDER BY
NULL値は数値、日付値、文字値のいずれの場合も、デフォルトでは「最も大きい値」として扱われます。
NULLS FIRSTとNULLS LAST
NULLの値に関しては最初に出てくるように調整するコードが「NULLS FIRST」
SELECT * FROM employees ORDER BY sal NULLS FIRST;
WHERE句とORDER BY句
この二つは同時に指定することが可能。
しかし順番は入れ替えることはできない。
where句の後にorder by句がくる。
例)次のコードはNULL以外の列でsalの昇順。(グラフに並び替えたときに登っていく)
SELECT * FROM employees WHERE sal IS NOT NULL ORDER BY sal;
SLECT句で指定しない列名でのORDER BY
SLECT句で指定しない列名でのORDER BYは
エラーにならない
列別名とORDER BYの関係
WHERE句には列別名は指定できませんが、
ORDER BY 句には列別名 を指定できます
row_limiting_clauseを使用
SELECT * FROM employees WHERE sal IS NOT NULL ORDER BY sal OFFSET ?? ROW(またはROWS) FETCH { FIRST | NEXT } { row_count | percent PERCENT } { ROW | ROWS } | { ONLY | WITH TIES }]
sample コード
先頭から5行をスキップした6行目から
3行分を取り出している。
SELECT empno, ename, sal FROM employees ORDER BY sal DESC 4 OFFSET 5 ROWS --先頭から5行をスキップした6行目から FETCH FIRST 3 ROWS --13行ぶんを取り出している WITH TIES;
sqlの「like」とは何か
sqlのlikeはパターン検索を可能にするキーワードです。
具体的には次のような場合に使います。
ある文字を含むものを条件に入れたい。
ある文字から始まるものだけを抽出したい。
基本的にはこの二つの用途しか使いません。
「sql ワイルドカード」で検索したあなたへ
「%(パーセント)」 任意の長さ(ゼロを含む)の文字列
「_(アンダーバー)」 任意の1文字
しかし基本的には%(パーセント)しか使わない。
「sql 特定の文字を含む」で検索した方へ
SQLのlikeで「特定の文字列を含む」場合を検索したい場合、次のように%で挟むことで記述できます。
select * from (テーブル名) where (カラム名) like '%検索したい文字列%'
例えば次のような「従業員テーブル」があったとします。
あなたは従業員の中でも「鈴木」から始まる従業員の人を探しています。
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | 鈴木 貴教 | 10,00 | 20 |
| 1235 | 鈴木 悟 | 20.000 | 20 |
| 1236 | nanashi | 30,00 | 10000 |
その時には次のようにlikeを使うことで「鈴木」を名前に含んでいる人を抽出することができます。
ポイントは「検索したい文字列を%で挟むこと」です。
select * from employees e where e.name like '%鈴木%'
- 実行結果
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | 鈴木 貴教 | 10,00 | 20 |
| 1235 | 鈴木 悟 | 20.000 | 20 |
従業員テーブルには「nanashi」さんもいますが今回は意図した通り「鈴木さん」だけが抽出されています。
「SQL 特定の文字列で終わる」で検索したあなたへ
特定の文字列で終わるクエリを書きたい場合は,特定の文字列の先頭に%をつけることで実現させることができます。
select * from テーブル名 where カラム名 like '%検索文字列'
例えば次の従業員テーブルで、名前が「悟」の人を検索したいと考えたとします。
- employeesテーブル
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | 鈴木 貴教 | 10,00 | 20 |
| 1235 | 鈴木 悟 | 20.000 | 20 |
| 1236 | nanashi | 30,00 | 10000 |
それもsqlのlikeを使えば簡単に実現できます。
ポイントは「検索したい文字列の先頭に%をつけること」です。
select * from employees where name like '%悟'
- 実行結果
| id | name | salary | dept_id |
|---|---|---|---|
| 1235 | 鈴木 悟 | 20.000 | 20 |
サンプルテーブル
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | 鈴木 貴教 | 10,00 | 20 |
| 1235 | 鈴木 悟 | 20.000 | 20 |
| 1236 | nanashi | 30,00 | 10000 |
その他の例(FRAQTAからの割り算の割り出し)
VB6,VBAのコードの中から「 / 」が含むSQLを全て割り出す必要が出てきた。
つまり割り算を炙り出さなければならないが、これがまた難しい。
しかしこの無理難題にもlikeを用いることで適切に対応することができた。
幸いにもFRAQTAには全てのソースコードが入っている。
select * from FRAQTA a where a.line like '%"%/%"%' and a.svn_repository_path IN ( "", "", ... "" )
SQL IN句
概要
この記事では「IN」の使い方とそのサンプルコードについて解説を行います。
「SQL IN」とは何か
SQLではIN句を使うことで「複数の選択肢のどれかに合致するもの」を抽出することができます。
「SQL IN 使い方」で検索したあなたへ
INとそれに続く括弧の中に検索したいキーワードを,区切りで入力することで複数条件に合致するものを抽出することができます。
例えば次のようなテーブルで、「部署コードが20か30」の従業員を取り出したいと考えたとします。
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | 鈴木 貴教 | 10,00 | 20 |
| 1235 | 鈴木 悟 | 20.000 | 20 |
| 1237 | 山田 悟 | 20.000 | 30 |
| 1236 | nanashi | 30,00 | 10000 |
このように「複数のキーワードのどれかに合致する」という条件を調べたい時は、INとそれに続く括弧の中に検索したいキーワードを,区切りで入力することで抽出することができます。
select from employees e where e.dept_id IN('20', '30')
- 実行結果
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | 鈴木 貴教 | 10,00 | 20 |
| 1235 | 鈴木 悟 | 20.000 | 20 |
| 1237 | 山田 悟 | 20.000 | 30 |
部署コード(dept_id)が20の人と30の人が抽出できています。
サンプルテーブル
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | 鈴木 貴教 | 10,00 | 20 |
| 1235 | 鈴木 悟 | 20.000 | 20 |
| 1236 | nanashi | 30,00 | 10000 |
CREATE句
新しいオブジェクトを作成するための句です
※CREATE系を実行した後は直後にCOMMITが自動実行されます。
CREATE TABLE文
表を作成するための句です
構文
CREATE TABLE [スキーマ名].表名 ( 列名 データ型 [,列名 データ型 ,列名 データ型 ... ] )
サンプルコード
CREATE TABLE employees ( empno NUMBER(4), ename VARCHAR2(20) )
スキーマについて
「論理的な概念」のこと
Oracleの各ユーザーは、ユーザー名と同じ名前のスキーマを一つ所有していおり、
各ユーザーが作成したオブジェクトは、そのユーザーが所有するスキーマに格納される
ただし論理的な概念であるため、領域とは別
自分が作ったオブジェクトには通常のアクセスができるが、
他のユーザーが所有するオブジェクトの三章では次のようにスキーマを指定する
スキーマ名.オブジェクト名
DEFAULTオプション
表の作成時に列の定義にデフォルトオプションを追加できる。
INSERT文で値を省略した際にはこの時に設定した値が適応される。
構文
CREATE TABLE [スキーマ名].表名 ( 列名 データ型 DEFAULT デフォルト値 [,列名 データ型 ,列名 データ型 ... ] )
- サンプルコード
CREATE TABLE employees ( empno NUMBER(4), ename VARCHAR2(20), hiredate DATE DEFAULT SYSDATE )
- INSERT時の挙動
INSERT INTO emp2(empno, ename) values (10, 'tarou'); SELECT * FROM emp2;
DEFAULTの値
リテラル値、式またはSQL関数を指定できる。(SYSDATE式やUSER式など)
クエリの結合
sql分で複数のテーブルを使用する場合の全てのパターンについて解説を行います。
サンプルテーブル
- employees
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | tarou | 10,00 | 20 |
| 1235 | kaiou | 20.000 | 20 |
| 1236 | nanashi | 30,00 | 10000 |
- Department
| id | name |
|---|---|
| 20 | 情報システム室 |
| 10 | 品質管理室 |
2種類の結合
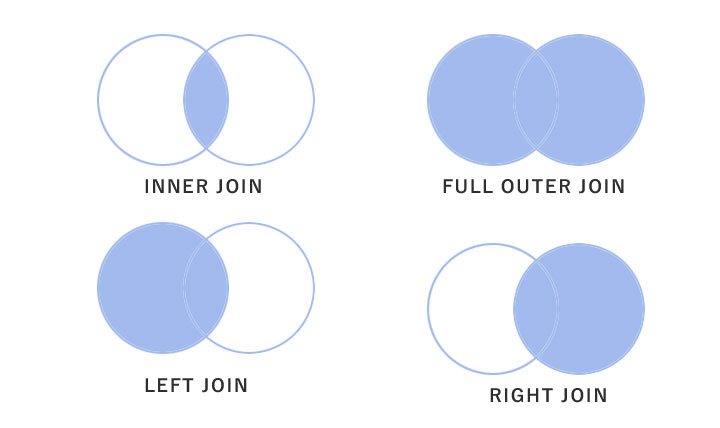
この図の通り、結合には大きく分けて2種類存在する。
- INNER JOIN(内部結合)
二つのデータベースを結合する際に、
両方のデータベースにデータが存在していれば
列が表示されるパターン。
通常の「結合」ではこちらを指すことが多い
- OUTER JOIN(外部結合)
二つのデータベースを結合する際に、
どちらかデータベースにデータが存在すれば
表示されるパターン
- Left Join, right join
この二つは少し例外で「Left Join」であれば
左側のデータベースに存在するものは全て表示する
というもの。
後付けで右側のデータベースがくっつくイメージ
INNER JOIN(内部結合)
二つのデータベースを結合する際に、
両方のデータベースにデータが存在していれば
列が表示されるパターン。
今回だと「従業員データベースと部署データベースに部署コードという共通の値が存在する場合のみ」が目的となる
通常、結合とはこのタイプの結合を表す。
- サンプルコード
select e.*, d.* from employees e, Department d where e.dept_id = d.id
純粋な結合のポイント
fromの中身のテーブルは「,」で区切ること
二つのテーブルを分けるために、「e」「d」などテーブルに別名(エイリアス)をつけること
そのための名前はわかりやすいもの(今回はemployeeとdepertmentの頭文字)にすること
結合する場所はwhere句の中で指定すること
内部結合の特徴
下記の従業員データベースではdept_idがNULLになっているnanashiは実行結果に表示されない。
これは、dept_idと同一の値(10000)が部署データベースのidカラムには存在しないためである。
- employees
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | tarou | 10,00 | 20 |
| 1235 | kaiou | 20.000 | 20 |
| 1236 | nanashi | 30,00 | 10000 |
実行結果
| id | name | salary | dept_id | id | name |
|---|---|---|---|---|---|
| 1234 | tarou | 10,00 | 20 | 20 | 情報システム室 |
| 1235 | kaiou | 20.000 | 10 | 10 | 品質管理室 |
LEFT JOIN
LEFT JOINはこちらの図の通り、左側のデータを絶対的な基準としてデータを表示したい場合に使われることが多い。
今回だと「従業員データベースのデータは全て表示し、そこの付随情報として部署コードを付け加える」というイメージ
- サンプルコード
select e.*, d.* from employees e LEFT JOIN Department d ON e.dept_id = d.id
実行結果
| id | name | salary | dept_id | id | name |
|---|---|---|---|---|---|
| 1234 | tarou | 10,00 | 20 | 20 | 情報システム室 |
| 1235 | kaiou | 20.000 | 10 | 10 | 品質管理室 |
| 1236 | nanashi | 10.000 | 10000 | NULL | NULL |
先程の内部結合とは違い、idがNULLであっても表示がされている。
「sql with」とは
SQLのwith文では
一度selectした結果の保存,使い回しを可能に
副問い合わせのネストの簡略化
「sql with 使い方」で検索したあなたへ
with の後に一時テーブル名を宣言 as のあとの括弧の内部にselect文を書くことで、テーブルの使い回し、副問い合わせのネストの簡略化が可能になる。
-- 宣言部分 with 一時テーブル as ( select ~ ) -- 再利用部分 select * from 一時テーブル
例えば、次の部署コードテーブルから部署一覧を取り出し、
その中の部署コードから従業員を取り出したい時
- employees
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | tarou | 10,00 | 20 |
| 1235 | kaiou | 20.000 | 20 |
| 1236 | nanashi | 30,00 | 10000 |
- Department
| id | name |
|---|---|
| 20 | 情報システム室 |
| 10 | 品質管理室 |
通常の副問い合わせだと次のようなクエリになる
select * from employee e where e.dept_id IN ( select id from department )
これは通常の理解可能な範囲であるが、通常ネストは少なければ少ないほどよい。
というわけで、with文を使うと次のようなコードになる。
with ALL_DEPTARTMENT_TABLE as ( select id from department ) select * from employee e where e.dept_id IN ALL_DEPTARTMENT_TABLE
二つのクエリとして分割することに成功し、
コードもグッと見やすくなった。
このように、with文を使うことでネストを浅くし、クエリを見やすくできる。
サンプルテーブル
- employees
| id | name | salary | dept_id |
|---|---|---|---|
| 1234 | tarou | 10,00 | 20 |
| 1235 | kaiou | 20.000 | 20 |
| 1236 | nanashi | 30,00 | 10000 |
- Department
| id | name |
|---|---|
| 20 | 情報システム室 |
| 10 | 品質管理室 |
title:「sql with」で検索したあなたへ【SQL基礎】
description:SQLのwith文では。一度selectした結果の保存,使い回しを可能にし、副問い合わせのネストの簡略化も実現できる。
img:https://www.oreilly.co.jp/books/images/picture_large4-87311-281-8.jpeg
{kind=link}
category_script:page_name.startswith("1")
概要:SQLの実行結果をファイル出力する
SQLを実行している時、まれにファイルに出力したくなる時があります。
例えばデータの状態を監視し、レポートを作成したい時など。
それを最も簡単にこなすのが「SPOOL」コマンドです
「SQL ファイル出力」で検索したあなたへ(SQL Plus)
SQL Plusでは 「SPOOL (ファイル名)」と記述することで指定したファイルに実行結果を全て吐き出すことができます。
SPOOL report
@run_report_output.pkg
SPOOL OFF
SQL Plusのデフォルトの拡張子は.lstで上記のコマンドではrepot.lstが作成され、そのファイル内に「@run_report_output.pkg」の実行結果が出力されます。
しかし、この拡張子はユーザー自身で塗り替えることが可能です。
例えば、report.textに出力したい時は
SPOOL report.text
@run_report_output.pkg
SPOOL OFF
page:https://minegishirei.hatenablog.com/entry/2023/02/11/094408