スペースベースアーキテクチャが解決する課題
ほとんどのWebアプリケーションは、次のような一般的なリクエストフローに従っている。
ブラウザからの要求は、Webサーバー、アプリケーションサーバーを経て、最後にデータベースサーバーに処理が移る。
このパターンは少数のユーザーには最適ですが、ユーザーの負荷が増えると、Webサーバー層、次にアプリケーションサーバー層、最後にデータベースサーバー層でボトルネックが発生し始めます。
ユーザー負荷の増加に基づくボトルネックへの通常の対応は、Webサーバーをスケールアウトすることです。
これは比較的簡単で安価であり、ボトルネックの問題に対処するために機能する場合がありますが、ボトルネックがアプリケーションサーバーに移動します。
そうしてアプリケーションサーバーの負荷をどうにかして減らせたとしても、最終的にはデータベースに負荷が移動するだけで根本的な解決にはなりません。
https://www.ulsystems.co.jp/archives/022.html
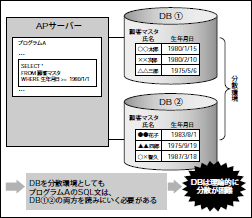
DBは業務に必要な情報を集約的に保持していることに価値があります。 逆に、DBにデータを分散して保持させることは困難だとも言えます。 もちろん、現在リリースされているRDBMS製品は、パーティションやレプリケーションといったデータを物理的に分散させる機能を提供しています。 しかし、DBの利用者から見ると、論理的には一元管理されているものとしてデータにアクセスしたいものです。 例えば、「顧客マスタ」データが物理的にはマシンAとマシンBに分散配置されているとしても、 「顧客マスタ」を扱うプログラムはマシンAとマシンB両方のデータを透過的に扱いたいはずです。
この問題を解消するのがスペースベースアーキテクチャです。
スペースベースアーキテクチャには、高いスケーラビリティと弾力性、並列処理といった問題に対応できる特性を持ちます。
特に、同時アクセス数ユーザーが予測できない場合に有効です。
スペースベースアーキテクチャの概要

スペースベースアーキテクチャの特徴は、アプリの標準的なトランザクションに中央のデータベースが関与しないことです。
これにより、データベースのトランザクションというボトルネックが解消されアプリケーションのスケーラビリティは無限になります。
中央のデータベースとの連携ではなく、各処理ユニットがメモリ内部にデータを持つのです。
そして、メモリ内部のデータが更新されると、更新情報が非同期的に他の処理ユニットに送られ、結果的に複製されます。
これらのメモリ内部でのデータ共有の技術をタプルスペースと呼ぶのです。
スペースベースのアーキテクチャのスペースとは、タプルスペースに由来します。
中央データベースをシステムの同期制約として削除し、代わりに複製されたメモリ内データグリッドを活用することで、高いスケーラビリティ、高い弾力性、および高いパフォーマンスが実現されます。
ユニット処理装置は、ユーザーの負荷が増減するにつれて動的に起動およびシャットダウンするため、スケーラビリティーが確保されるのです。
スペースベースアーキテクチャの構成要素
- 処理ユニット(Processing Unit)
アプリケーションコード、メモリ内部のデータグリッド、データ複製エンジンを含む。
- データリーダー(DataReader),データライター(DataWriter)
非同期方式で処理ユニットのデータを受け取り、中央のデータベースにメッセージを送る
- 仮想ミドルウェア(Virtualized Middleware)
処理ユニットの管理・調節に使用される
スペースベースアーキテクチャの処理ユニット
アプリケーションコード
ここには通常、webフレームワークなどのバックエンドのビジネスロジックが含まれており、ある種一つのアプリケーションが完成している。
また大規模なアプリケーションでは、以下のように処理ユニットが複数種類に分割される可能性がある。

例えば、個人情報の漏出ニュースが流れ会員ページへのアクセスが集中する場合は、Profile Process Unitを複製することでバーストに耐えることができる。
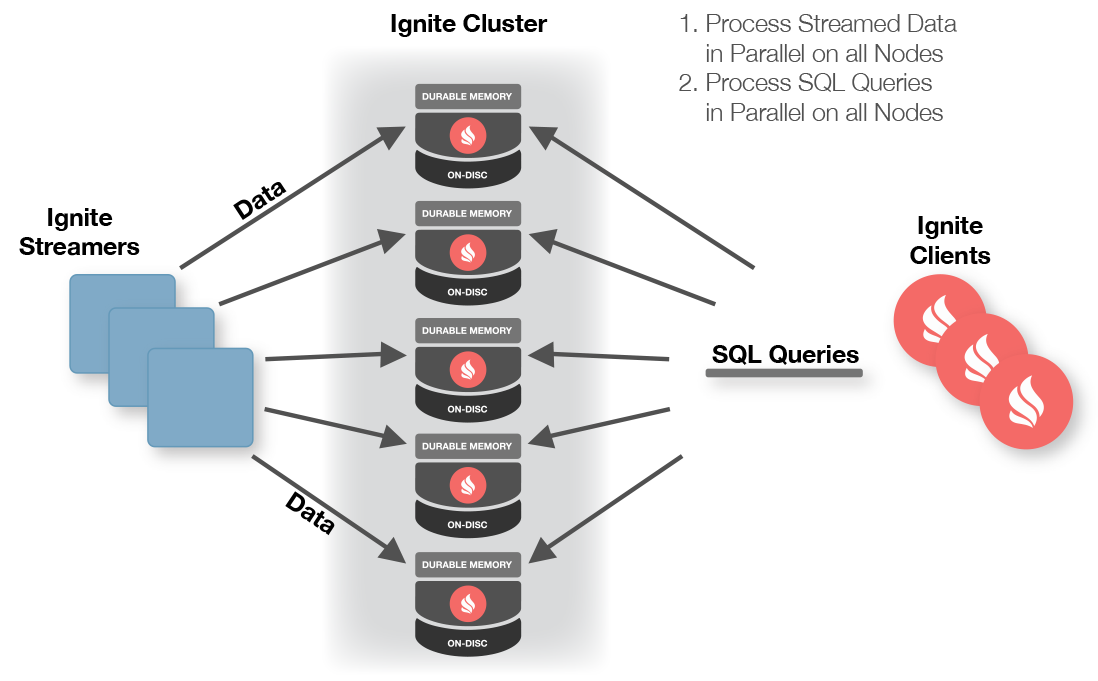
インメモリデータグリッドとレプリケーションエンジン
処理ユニットには通常、インメモリデータグリッドとレプリケーションエンジンも含まれる。
これらの製品を通じて実装されるものである。
https://www.gridgain.com/resources/blog/using-gridgainr-kafkar-connector
サンプルコード
Hazelcastを使ったJavaコードによる実装は以下の通り
HazelcastInstance hz = Haxzelcast.newHazelcastInstance();
Map<String, CustomerProfile> profileCache =
hz.getReplicatedMap("CustomerProfile")
顧客情報へのアクセスを必要とするすべての処理ユニットには、このようなコードが含まれる。
いずれの処理ユニットからCustomerProfileというキャッシュへの変更は、Hazelcastの本体を通じて複製される。
複製されたキャッシュが一つでも存在していれば、あたらしいインスタンスを立ち上げたときでもデータベースからの読み込みを必要とせず、結果的に処理が早くなるということだ。
Hazelcastの仕組みについて
処理ユニットが一つだけの場合、Hazelcast本体のログは次のようになる
Members {size:1, ver:1} [
Member [172.19.248.89]:5701 - 04a6f863-dfce-41e5-9d51-9f4e356ef268 this
]
ここでは、以下の点に注目してほしい
ここからインスタンスが複数に増えるとき、ログは次のように変化する。
Instance 1:
Members {size:2, ver:2} [
Member [172.19.248.89]:5701 - 04a6f863-dfce-41e5-9d51-9f4e356ef268 this
Member [172.19.248.90]:5702 - ea9e4dd5-5cb3-4b27-8fe8-db5cc62c7316
]
Instance 2:
Members {size:2, ver:2} [
Member [172.19.248.89]:5701 - 04a6f863-dfce-41e5-9d51-9f4e356ef268
Member [172.19.248.90]:5702 - ea9e4dd5-5cb3-4b27-8fe8-db5cc62c7316 this
]
このログから、あるインスタンスがほかのインスタンスの情報を完璧に保持していることが把握できるだろう。
これらのインスタンスは常に非同期通信で繋がっており、あるインスタンスのmethodで、cache.put()のようなキャッシュ更新methodを使用すると、Hazelcastはその更新をほかのインスタンスへ通知するのだ。
仮想メモリ内部のデータグリッド
このインメモリデータは、仮想メモリ内部にあるデータグリッドにも存在することがある。
これは、外部からのメモリデータをコントロールする意図で設置される。
仮想メモリ内部のデータグリッドを変更することで、非同期で処理ユニット内部にあるインメモリデータグリッドが同期されるのだ。
仮想ミドルウェア
データの同期やリクエスト処理の様々な側面を制御するアーキテクチャ内部のインフラストラクチャに関する問題を処理する。
この仮想ミドルウェアを構成するのは次の4つの要素からなる
メッセージンググリッド(役割はロードバランサー)
データグリッド(メモリデータの中央)
処理グリッド
デプロイメントグリッド
メッセージンググリッド
入力されたリクエストやセッションの状態を管理する
ユーザーからメッセージを受け取ると、どのアクティブな処理コンポーネントがリクセストを受信できるかし、それらの処理ユニットの1つに要求を転送します
メッセージンググリッドの複雑さは、単純なラウンドロビンアルゴリズムから、どの要求がどの処理ユニットによって処理されているかを追跡する、より複雑な次に利用可能なアルゴリズムにまで及ぶ可能性があります。
このコンポーネントは通常、負荷分散機能を備えた一般的なWebサーバー(HA ProxyやNginxなど)を使用して実装されます。
処理グリッド
処理グリッドは、仮想化ミドルウェア内のオプションのコンポーネントであり、一つのリクエストに複数の処理ユニットの協調が必須となる場合に、それらの処理の指揮、オーケストレーションを行います。
たとえば、注文処理ユニットと支払い処理ユニット間の調整を必要とする要求が来た場合、これら2つの処理ユニット間の要求を仲介および調整するのは処理グリッドです。

デプロイメントマネージャー
デプロイメント・マネージャー・コンポーネントは負荷条件に基づいて処理装置インスタンスの動的な始動とシャットダウンを管理します。
このコンポーネントは、応答時間とユーザーの負荷を継続的に監視し、負荷が増加すると新しい処理装置を起動し、負荷が減少すると処理装置をシャットダウンします。
これは、アプリケーション内で可変のスケーラビリティ(弾性)のニーズを達成するための重要なコンポーネントです。
データポンプ
データポンプは、データベース内のデータを更新する別のプロセッサにデータを送受信する方法です。
データポンプは通常、メッセージング(JSON,XMLなど)を使用して実装されます。
データポンプは本質的にはデータ抽出層なるものを形成する。
あるいは、データアクセス層となるか。
データアクセス層とは処理ユニットがデータベースの基礎となるデータ構造に結合されており、データリーダーとライターを用いてアクセスするだけのものである。
一方のデータ抽出層とは処理ユニットが個別のコンストラクトによってデータベースの基礎となるテーブル構造から切り離されていることを意味する。
一般的にスペースベースアーキテクチャではこちらを採用する。
データライター
データライターコンポーネントは、データポンプからのメッセージを受け取り、データポンプのメッセージに含まれる情報でデータベースを更新します。

また、データポンプ一つに対してデータライターが一つつくこともあります。

データリーダー
データリーダーはデータベースからデータを読み取り、リバースデータポンプを介して処理ユニットに送信する責任を負います。
スペースベースのアーキテクチャでは、データリーダーは次のいずれかの状況で呼び出されます。
すべてのインスタンスがダウンした場合(システム全体のクラッシュまたはすべてのインスタンスの再デプロイが原因)、データをデータベースから読み取る必要があります(スペースベースのアーキテクチャでは一般的に回避されます)。
スペースベースアーキテクチャの具体例
スペースベースアーキテクチャは、ユーザーからのリクエストが増加するアプリケーションや同時使用ユーザー数が10000人を超えるようなスループットのアプリケーションに適している。
具体的には、次のようなシステムだ。
オンラインのコンサートチケット販売システム
オークションシステム
これらの例はいずれも高パフォーマンス、高スケーラビリティ、高レベルの弾力性が求められる。
特に、オンラインのコンサート販売チケットシステムは、ある期間ではまったく使われなかった中で、ユーザー数が爆発的に増加する瞬間がある
この状態では中央のデータベースにアクセスし続けるようなシステムはおそらくうまくいかない。データベースでは大量のトランザクションを並列で捌くのは非常に困難だ。
一方スペースペースアーキテクチャでは、アーキテクチャに標準搭載されているデプロイメントマネージャーがユーザー数の増加を自動的に検知し、大量のリクエストを捌くために必要となる大量の処理ユニットを起動してくれる。
スペースベースアーキテクチャでは、特別な改修を行わずに、大量のリクエストを捌くための処理が備わっているのだ。
備考
title:スペースベースアーキテクチャのメリットデメリット
description:スペースベースアーキテクチャの概要と構造、メリットとデメリットを解説します。
category_script:( page_name.startswith("2") or page_name.startswith("1") )
page:https://minegishirei.hatenablog.com/entry/2023/01/29/090131